第236回「生成AIで医療の質向上へ」
急速に浸透
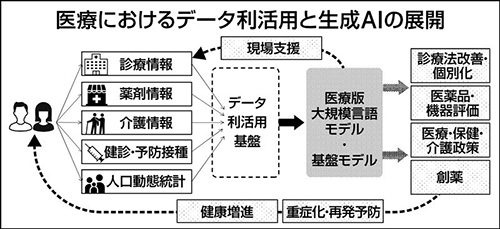
チャットGPTに代表されるように生成人工知能(AI)の進化が著しい。医療分野においても、大量かつ多様な言語データを学習した生成AI「大規模言語モデル」の活用が急速に進んでいる。米国では、マイクロソフトやアルファベットなどのビッグテック企業が、医療に特化した大規模言語モデルの開発に取り組むとともに、電子カルテとAIを組み合わせる実証実験を行っている。具体的には、例えば医療現場における診療記録作成の補助、問診結果に基づく疾病候補の提示などの検証が進んでいる。
大規模言語モデルの実装が進みつつある中、言語だけでなく画像や音声なども含めた大量のデータを学習して作られ、多種類のデータを一度に処理できる、いわゆるマルチモーダルな基盤モデルが注目されている。このような技術を医療分野にカスタマイズした「医療版基盤モデル」の出現により、例えば医師が医用画像や図表を含む論文の内容を深く迅速に理解し、その知見を日常の診療に活用することで、医療の質が向上する可能性がある。
医療における生成AIの利活用には懸念もある。生成AIの問題として「ハルシネーション」(生成AIがもっともらしい虚偽情報を生成すること)が指摘されている。また、不当な差別などの倫理的に適切でないアウトプットを完全に排除することも困難である。生成AIのこうした問題の解消に向けた研究開発と並行して、医師の責任下で行われることを前提とした使用ルールや関連する法規制の整備が必要である。
データ集め課題
生成AIの開発は米国を筆頭に海外が先行している。日本においても、業務効率化による医療従事者の長時間労働是正などへの期待から、医療分野向けの生成AI開発と活用の動きが活発になりつつある。開発を進める上では、AIを研究する人材や計算資源の確保に加え、学習に必要なデータの確保が課題となる。
日本では、国民皆保険や定期健康診断などの健康・医療政策を背景として良質な健康・医療データが大量に生産されてきたが、それらは今まで各現場に散在しており、共用されずにいた。「ビッグデータは21世紀の新たな資源」と言われるが、資源は採掘し手を加えることで初めて価値を生み出す。個人情報保護や倫理面での懸念に配慮しつつ、生成AIの研究開発を契機として、わが国の健康・医療データの利活用が加速することを期待したい。
※本記事は 日刊工業新聞2024年4月5日号に掲載されたものです。
<執筆者>
宮薗 侑也 CRDS元フェロー(ライフサイエンス・臨床医学ユニット)
東京大学大学院新領域創成科学研究科博士課程修了、博士(科学)。計測機器企業にて製品開発に従事。2020年よりJSTに出向し、生命科学系計測や健康・医療データ活用に関する調査を担当。
<日刊工業新聞 電子版>
科学技術の潮流(236)生成AIで医療の質向上へ(外部リンク)