第213回「生成AIの技術開発課題」
基盤モデル
チャットGPTに代表される生成人工知能(AI)は、言葉による指示に対して、まるで人間のような自然な応答や、専門的な知識と能力を備えているかのような応答を返す。人間の知的作業全般に急速な変革をもたらし、産業、研究開発、教育、創作などさまざまな分野に幅広く波及すると、大きな話題になっている。
生成AIは膨大な量の文章から言葉の関係を学習して、次に続く言葉を予測することで応答を返している。言葉と画像の関係も学習して、言葉に応じた画像の生成も可能である。このような膨大なマルチモーダルデータを学習して作られた予測モデルは、米国スタンフォード大学の研究チームによって「基盤モデル」と名付けられた。
超大規模な基盤モデルを用いて高い汎用性を実現した生成AIは、オープンAIやグーグルなどの米国ビッグテック企業が多くの利用者を獲得し、開発で先行している。
経済や社会へのインパクトも大きく、この半年ほどの間に、多数の企業や研究機関が基盤モデルと生成AIの開発・利活用に参入した。倫理的・法的・社会的問題に対する規制の国際的議論も行われている。
課題の全体像
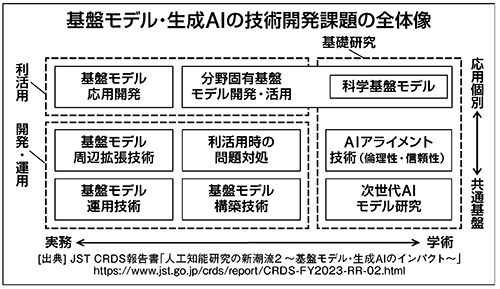
ここにはさまざまな技術開発課題があることを踏まえて取り組む必要があり、その全体像を図に示した。図の左下部は「開発・運用」に関する取り組みであり、基盤モデルの開発・運用に加えて、利活用のための周辺機能やルールの整備を含む。上部は「利活用」に関する取り組みであり、既存の生成AIの応用開発、分野や用途に適した固有モデル開発を含む。右部は「基礎研究」の取り組みであり、現状の基盤モデルの理解や発展、その限界を超える次世代モデルの創出、倫理性や信頼性の確保、科学研究の革新などを含む。
日本は労働人口の減少に直面しており、生産性向上、産業成長につながる「利活用」は期待が大きい。「開発・運用」は米国ビッグテック企業の後追いになるが、経済安全保障の面でも、「利活用」「基礎研究」を支えるという面でも、国産基盤モデルを持っておくことは必要と考えられている。
さらに、今は後追いであっても、次世代モデルで先行するには「基礎研究」がカギとなる。これら三つへの取り組みをうまく連動させて推進することが必要であろう。
※本記事は 日刊工業新聞2023年9月29日号に掲載されたものです。
<執筆者>
福島 俊一 CRDSフェロー(システム・情報科学技術ユニット)
東京大学理学部物理学科卒、NECにて自然言語処理・情報検索の研究開発に従事後、2016年から現職。工学博士。11-13年東京大学大学院情報理工学研究科客員教授、情報処理学会フェロー。
<日刊工業新聞 電子版>
科学技術の潮流(213)生成AIの技術開発課題(外部リンク)