成果概要
誰もが自在に活躍できるアバター共生社会の実現[3] CAの認識能力や操作者の意図理解に必要となる人間の知識や概念の獲得に関する研究開発
2024年度までの進捗状況
1. 概要
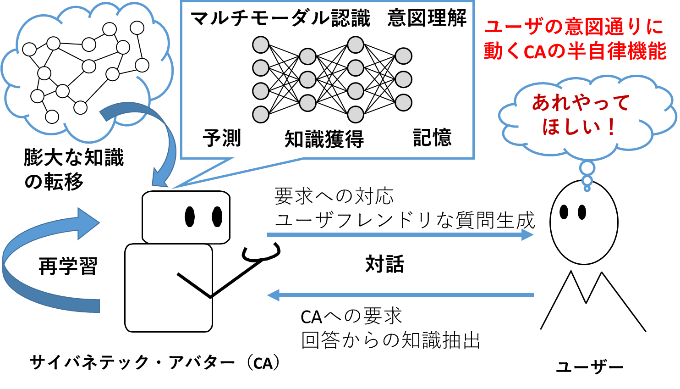
この研究開発課題では、ユーザの意図通りに動くサイバネティックアバター(CA)の半自律機能実現のために、高度な認識能力、CA間での知識共有、操作者の意図理解に必要となる人間の知識や概念の獲得についての研究開発に取り組んでいます(図1)。
この知識と概念の獲得には、視覚情報に人間レベルの知識や概念を組み合わせ、さらに自然言語も含めた多様なモダリティの情報を組み合わせる必要があります。また、視覚情報や自然言語などの様々なモダリティの融合と、多様な実環境における知識共有や獲得を目的とした対話の実現によって、CAが人間と共有できる知識や概念を獲得することを目指します。さらに、得られた知識や概念を基盤とした観測や対話をおこなうことで、操作者や利用者の意図理解につなげていきます。CA、操作者、利用者間でのやり取りは、得られるデータ量も多くはないため、少ないデータでも学習可能な新たな学習手法等を開発します。
2. これまでの主な成果
意図理解と知識共有のためには、CAとユーザの間で円滑なコミュニケーションを成立させることが不可欠です。三次元ヘッドアバターは、そのための対話インタフェース/観測・表現基盤として重要な役割を担います。三次元ヘッドアバターを用いることで、表情・視線・口唇運動といった非言語情報を高精度に提示・取得でき、これらを発話内容と統合して解釈することで、相互理解を促進し、対話を通じた人間の知識や概念の獲得、さらには意図理解の精度向上につながります。
三次元ヘッドアバターとは、人間の頭部を立体的に再現したデジタルモデルであり、顔の形状や表情、視線、口の動きなどを高精度に再現可能です。近年、メタバースや遠隔コミュニケーション、医療支援、教育、接客ロボットなど多様な分野で活用が進んでいます。本人に似たアバターを介することで、非対面でも自然で信頼感のある対話が可能となり、社会的・身体的制約を超えたコミュニケーションの実現に寄与しています。また、高齢者や障がい者など多様な人々の社会参加を促進する技術としても注目されています。
既存の三次元ヘッドアバター手法は、二次元ベースのワープ、メッシュベース、およびニューラルレンダリングアプローチに分類され、多視点一貫性の維持、非顔部情報の取り込み、および新しい個人への汎化において課題を抱えています。本テーマでは、一枚または複数の画像から単一のフォワードパスで三次元ヘッドアバターを再構築するフレームワークGPAvatarを提案しました。本手法の技術的新規性は、ポイントクラウド駆動の表現フィールドを導入することで、表情の正確かつ効果的な捕捉を可能としたことです。さらに、新たな注意モジュールを採用することで、複数の入力画像からの情報を活用することが可能です。提案手法は、個人の一貫性を忠実に保った再構築、正確な表情制御、多視点一貫性を実現し、自由視点ポイントレンダリングと新規視点合成において有望な結果を示しています。
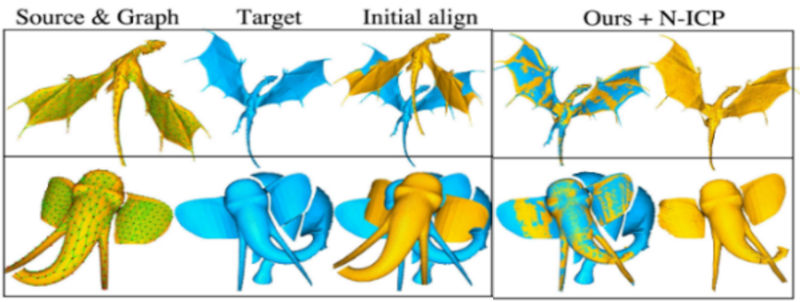
さらに2024年度の後半ではGPAvatarの改良を行いました。GPAvatarはニューラル放射場(NeRF)に依存しており、レンダリング負荷が高く、生成速度が遅いという課題を抱えていました。そこで本テーマでは、単一画像から単一フォワードパスで再構築可能な汎用性が高くアニメーション可能なガウスヘッドアバター(GAGAvatar)を実現しました(図2参照)。本研究の技術的新規性は、個人の一貫性と顔の細部を捉える高忠実度の三次元ガウス分布を生成するデュアルリフティング手法です。さらに、大域的画像特徴と三次元変形可能モデルを活用し、表情制御用の三次元ガウス分布を構築します。学習後、提案モデルは特定の最適化なしで初見の個人を再構築でき、リアルタイムでの生成レンダリングを実現します。実験結果から、提案手法は再構築品質と表情精度において既存手法を凌駕する性能を示しています。
3. 今後の展開
今後は、各要素の高度化と統合に挑戦することで、CAの認識能力の向上と人の意図理解の達成につなげていきます。