Progress Report
Integration of Asian humanities and brain informatics to enhance peace and compassion of the mind[1] Data-driven modeling
Progress until FY2024
1. Outline of the project
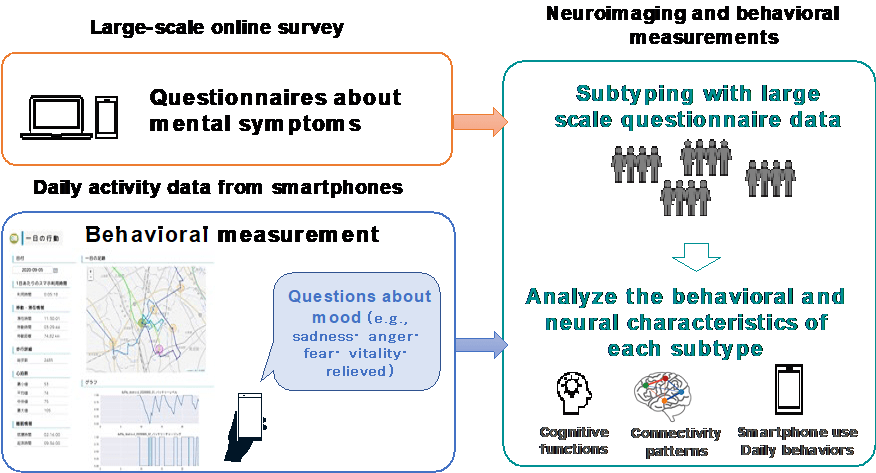
To construct a model for categorizing personality types using a data-driven approach, we began developing the foundational “High-low Mixed Database” (Figure 1). Specifically, we designed survey questions and smartphone-based daily behavior tracking items for the “low” component and completed the first large-scale survey. We also conducted brain imaging experiments for the “high” component.
2. Outcome so far
Item 1: Data-driven modeling
- (1) Formulation of the Basic Design of the "High-Low Mixed Database"
- Together with Research Tasks 2 and 3, we developed and administered a large-scale online survey of 3,800 participants using the finalized questionnaire items regarding personal traits (“low” data). Among these respondents, 141 individuals were selected for behavioral tracking experiments and 25 for fMRI experiments. As a result, the first phase of large-scale data collection has been completed, yielding a total of 10,565 questionnaire responses and behavioral data from 433 individuals through daily life monitoring and experience sampling.
- (2) Construction of a Data-Driven Model for Categorizing Personality Types Related to Serenity and Vitality
- Using a protocol co-developed with Task 3, fMRI experiments, cognitive function behavioral batteries, and decision-making trait assessments were conducted on 25 individuals. These data were stored in a database system (XNAT). With this, we acquired MRI data for a total of 51 individuals, and together with the “low” data, completed the construction of the Phase 1 High-low Mixed Database.
Item 2: Large-scale survey using the Internet and smartphones
In collaboration with Research Tasks 2, 3, and Task 3 of the Social Implementation Team, we conducted an online full-scale study and behavioral tracking experiments with 3,800 participants. Additionally, behavioral tracking and ecological momentary assessment were carried out with 141 individuals (Figure 2).

Item 3: Optimization of data-driven analysis
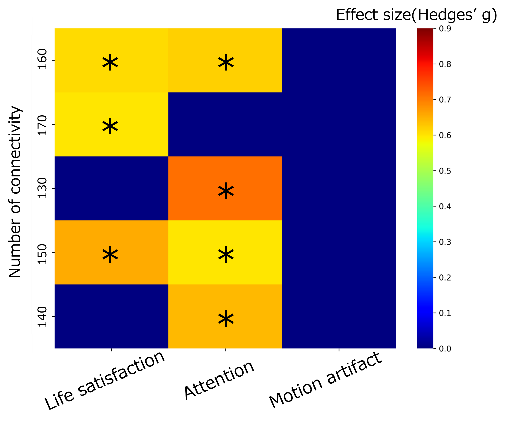
We rigorously evaluated the test-retest reliability and stability of 160 resting-state functional connectivities (FCs) features previously identified as optimal for hierarchical supervised-unsupervised learning in healthy subjects. Clustering models based on these 160 FCs were compared, with the top 1,000 models (by likelihood) shown in Figure 3 (upper left). Analysis of the Adjusted Rand Index (ARI) across the top 20 models indicated that models ranked 4–20 shared high similarity, suggesting they are highly generalizable (Figure 3 upper right). The model with the highest ARI was selected as the optimal model for clustering (Figure 3 lower). Results showed that the frontoparietal and somatosensory networks—previously implicated in depressive symptoms and treatment prediction—played a major role.

3. Future plans
Using the High-low Mixed Database, we aim to identify stable personality types through data-driven classification.