

研究への情熱映像と取材記事


深層学習の潜在的正則構造の理解に基づく学習法の安定化と高速化
- 深層学習の理論解析
二反田 篤史
(九州工業大学 大学院情報工学研究院 准教授)
さまざまな分野のサービスや製品に活用されるAI技術。その中でも代表的な深層学習(ディープラーニング)は、脳神経回路を参考にしたモデルを用いた機械学習だ。データに潜むルールやパターンなどを人間が推論するように、膨大なデータから導くことができる。しかし一方で、“なぜ”うまくいくのか、よくわからないまま実用化が進んでいる現状がある。さきがけの研究で二反田さんは、この問題について数学的な観点から説明できる糸口を見いだした。
うまくいく理由を説明できれば、深層学習はさらに使いやすい道具になる

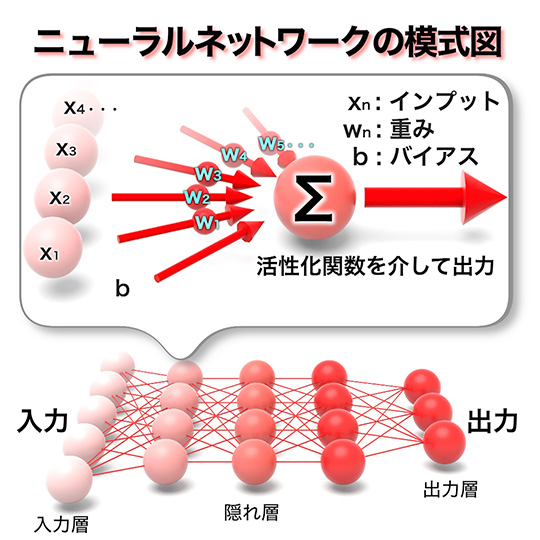
コンピュータの登場以降、幾度となくブームとなり注目された人工知能(AI)は、深層学習の登場によって、飛躍的に実用化が進んだ。深層学習は機械学習の手法の一つで、ヒトの脳を数学的に模倣したニューラルネットワークを用いる。人工ニューロン(ノード)がネットワークを形成し、ヒトのニューロンが入力の電気信号に応じた出力をするときと同様に、他のノードとの結合強度(重み)などを調節する訓練によって、学習を進めるアルゴリズムだ。
深層学習では、膨大なデータで訓練しパターンや特徴を抽出する。このため、人間がルールを与える必要がない。さらに未知のデータに対しても、この“知識”を当てはめ予測することができる。例えば、犬と猫の画像を学習させると新しい画像に対しても犬猫を区別できる。しかし、「学習時にチューニングできるパラメータ数が膨大なニューラルネットワークは、とても表現力が高い関数であるため、学習データにだけ適応し未知のデータについて推定する能力が下がる、過学習が起きる可能性があります。従って、なぜ汎化性※が高い学習結果が得られるかは、完全にはわかっていません」と二反田さんは語る。
深層学習は、経験的な知識を積み重ねながら発達してきた。例えば、画像解析に対し、どのようなネットワークの形、パラメータ設定、チューニング方法が適しているかなど、さまざまな事例で得られた知識が論文等で共有され、急速に実用化が進んだ。このため深層学習には経験に基づく職人的な作業が必要となり、商用利用される巨大なニューラルネットワークのチューニングともなれば、試行錯誤を重ねる作業量は膨大なものとなる。さらに近年、問題視されているのが二酸化炭素の排出量だ。深層学習の訓練には大量の電力を要することが報告されている。
今後、深層学習の需要はますます高まることだろう。しかし、将来に渡って持続的な技術として利用するためには、このようなコストを削減していくことが求められる。「性能のために無限にコストをかけることはできません。そこにはトレードオフが存在します。現在は設定を網羅的に試すしかないのですが、効率よく訓練するためには、適切な方法を選択できる“指針”が必要です」と二反田さんは理論的な枠組みの重要性を指摘する。
一般に機械学習では、できるだけ正解に近い予測値を出力できるように、モデルのパラメータをチューニングする。つまり学習とは、正解(データ)と予測値の誤差を測る関数(目的関数)の最適化と言い換えることができる。古典的な機械学習の仕組みやチューニング方法(最適化手法)は、深層学習よりずっとシンプルだ。例えば、機械学習の手法として広く用いられるカーネル法では、目的関数は解が一つに定まる強凸関数なので、その汎化性なども説明できる。一方、深層学習はその複雑さゆえ、目的関数は非凸関数で複数の局所解が存在する。「深層学習には最適ではない解がいくつも存在します。それにも関わらず、“うまい設定”による学習では、なぜ他の局所解に囚われず最適な解に収束するのか、なぜ選択した最適化手法が妥当なのか。そうしたことを説明できる数学的な理論を見いだしたいと考えました」。
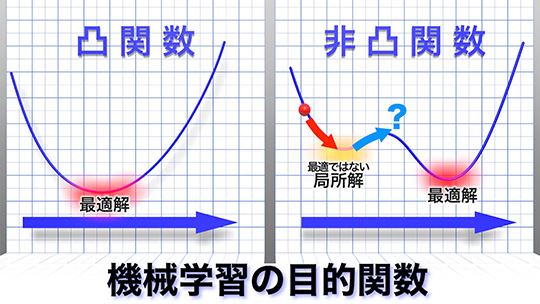
しかし、有限個のニューロンとパラメータによる学習は非凸関数の最適化問題であり、解析は困難だ。そこで二反田さんは、パラメータの見方をかえることを思いついた。「まずは簡単な二層ニューラルネットワークにおいてニューロンが無限個ある状態を考えました。するとパラメータは確率分布として表され、学習は確率分布を変数とした、凸関数の最適化とみなすことができます」。二反田さんは、標準的な最適化手法によるパラメータの確率分布の変化を解析することで目的関数を最適化できることを数学的に示し、計算機を使った実験で同じように最適な状態に収束することを実証した。そして、成功の要因を「ある確率分布に従った乱数を得る方法をサンプリングといい、サンプリングのアルゴリズムは確率分布の最適化問題に帰着することが知られています。同じような見方ができそうだと、気付いたのがきっかけでした」と振り返る。
この解析はシンプルな二層ニューラルネットワークを対象としたものだが、深層学習の理論構築に道筋をつける第一歩となった。二反田さんはさらに「ニューラルネットワークの構造によって、学習効率はかなり変わるので、もっと複雑な構造のニューラルネットワークにも議論を拡張することを目指したいです。また、今回の研究で開拓した理論解析手法は、さまざまなアプリケーションにも適用できるので、他の具体的な応用例も増やしていきたい」と今後の展開に意気込みをのぞかせる。機械学習はさかんに活用され、プログラムパッケージも数多く実装されている。そこに深層学習の理論解析の知見が加われば、最適な設定を選択するための実践的な“指針”を提供できることだろう。「“なぜか”できる」から、「“だから”できる」になることで、深層学習はさらに使いやすく、強力な道具になる。コストと環境負荷の低減にもつながることは言うまでもない。

※未知のデータに対する学習モデルの予測性能のこと。
*取材した研究者の所属・役職の表記は取材当時のものです。
研究について
この研究は、さきがけ研究領域「数学と情報科学で解き明かす多様な対象の数理構造と活用(坂上貴之研究総括)」の一環として進められています。また、さきがけ制度の詳細はこちらをご参照ください。

