 課題情報
課題情報
バイナリー静的解析による不正機能および脆弱性の検証技術の研究
研究開発内容
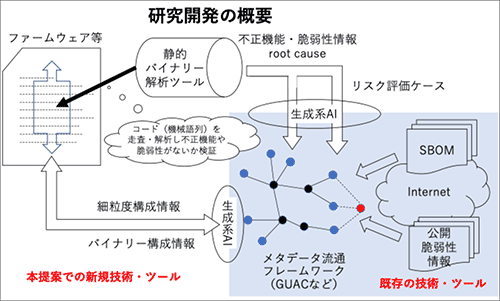
本研究開発では、ファームウェア等に不正機能や脆弱性が存在するかを、プログラム実行やソースコード参照を行うことなく検証する自動化技術を開発します。プログラム解析技術に加えて生成系AI技術を活用することで、人手による作業なしに自動検証が行えるようにします。検証結果に加えて、機能を単位としたソフトウェアの構成情報やリスクを明確に説明するリスク評価ケースを提供することで、利用者による不正機能や脆弱性への対応を支援します。
- (研究開発項目1)バイナリー静的解析ツールの開発
- (研究開発小項目1-1)フロントエンド内製
IT機器はさまざまな種類のマイクロプロセッサーで実装されているため、ファームウェアも異なる種類の機械命令のバイナリーコードで構成されています。さまざまなファームウェアを共通の手法で解析するためには、異なる種類のバイナリーコードを共通の中間表現に変換するフロントエンド部が必要です。オープンソースツールを用いてフロントエンド部を開発し、ツールが広く用いられるようにします。
- (研究開発小項目1-2)解析コア部開発
共通の中間表現形式に変換されたバイナリーコードを解析し、不正機能や脆弱性が存在するかどうか検証します。レジスターやメモリに格納されるデータの流れを追いかけて、コマンドインジェクションやバッファーオーバーフローなどの脆弱性やバックドア設置などの不正機能が存在しないかを調べます。プログラムを実行させて確かめるのではなく、機械命令の意味に従ってデータ値を評価するため、網羅的な検証が可能になります。
- (研究開発小項目1-3)テイント解析部開発
攻撃者が不正機能や脆弱性を悪用するには、攻撃者自らがプログラム内部にデータを送り届けることが必要です。こうした悪意あるデータをテイントデータ、その流れをテイントパスとそれぞれ呼びます。テイントパスを同定した上で、悪用可能な不正機能や脆弱性の検証を行うことが、解析の効率向上に非常に重要です。テイントパスを効率よく列挙するテイント解析部を開発します。
- (研究開発小項目1-1)フロントエンド内製
-
(研究開発項目2)不正機能や脆弱性のリスクを説明するリスク評価ケースの作成支援
-
(研究開発小項目2-1)記述実験
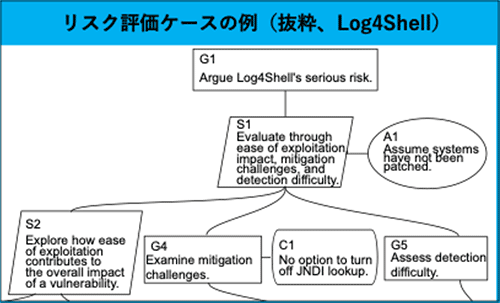
発見された不正機能や脆弱性のリスクの大きさを説明するために、アシュアランスケースの手法に倣ったリスク評価ケースを作成・共有することで、サプライチェーン全体での不正機能や脆弱性への対応を促進します。既存の脆弱性情報を補完するものとして、代表的なケースについての記述実験を行い、記述パターンを確立させます。
-
(研究開発小項目2-2)ガイドライン作成
記述実験の結果を踏まえて、リスク評価ケースをどのように記述するかを説明したガイドライン文書を開発します。
-
(研究開発小項目2-3)支援ツール整備
リスク評価ケースはグラフ状の構造化文書ですので、これを作成するためのツールや定型的な記述を支援するマクロ機能などの支援が必要です。既存ツールを用いてリスク評価ケースを効率よく記述する活用方法を整備します。
-
(研究開発小項目2-1)記述実験
-
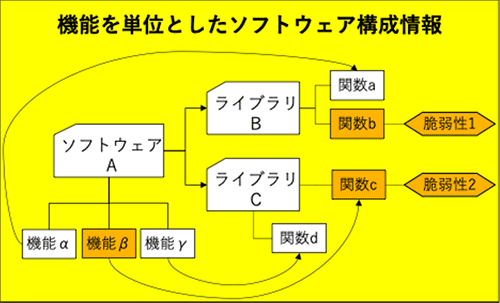
(研究開発項目3)細粒度ソフトウェア構成情報の抽出
サプライチェーンの中で発見された不正機能や脆弱性に対応するためには、影響を受けるソフトウェアを迅速に同定できることが重要です。SBOM(Software Bill of Materials)の利用が推奨されていますが、SBOMでの依存性定義は粒度が粗いため、実際には必要のない作業が多く発生する恐れがあります。この問題に対応するため、粒度の細かい機能単位での依存関係を抽出し共有する手法を開発します。
-
(研究開発項目4)コード生成言語モデルによるバイナリーコード解析支援
-
(研究開発小項目4-1)フロントエンド学習
フロントエンド部の開発では、プロセッサーアーキテクチャーごとに中間表現への変換モジュールを開発するため、大きな労力が必要となります。コードを対象とした大規模言語モデルを活用すれば、こうした変換を学習により自動化できる可能性があります。コード生成言語モデルを学習・微調整する手法について研究します。
-
(研究開発小項目4-2)テイントパス提示
データフロー追跡のアルゴリズムで計算するのではなく、コード生成言語モデルへ問い合わせることで、テイントパス候補を列挙できることが知られています。こうした処理の性能を向上させる手法について研究します。
-
(研究開発小項目4-1)フロントエンド学習