









プロジェクト概要
計算機は,産業プロセスの最適化や解析,マーケティング,バイオインフォマティクスなど,様々な情報処理に活用されています.近年の爆発的に増大している大規模データを処理するためには,計算機ハードウェアの高速化だけでなく,膨大な離散構造データ(計算機が行う論理的な処理を表現したデータ)を数学的に簡約化し効率よく計算する「アルゴリズム技術」の重要性が高まっています.本研究領域では,基本的な離散構造の1つである論理関数を処理するBDD(Binary Decision Diagram:二分決定グラフ)と,さらにその進化形であるZDD (Zero-Suppressed BDD; ゼロサプレス型BDD)の2つの技法を基盤とした離散構造処理系の研究に取り組んでいます. ZDDは、研究総括が独自に考案したBDDの進化形で,疎な組合せの集合を効率よく処理する技法として世界的にも注目されています.これらの技法をさらに発展させ,多様な離散構造を統合的に演算処理する技法を体系化し,システム検証や最適化,データマイニング,知識発見などを含む分野横断的かつ大規模な実問題を高速に処理するための技術基盤を構築していく予定です.
技術的背景
離散構造は,離散数学および計算機科学の基礎をなすものであり,集合理論, 記号論理,帰納的証明,グラフ理論,組合せ論, 確率論などを含む数学的な構造の体系である. およそ計算機が扱うあらゆる問題は, 単純な基本演算機能を要素とする離散構造として表現することができ, そのような離散構造の処理に帰着される.
離散構造の処理は, 最終的には膨大な個数の場合分け処理を必要とすることが多い. 種々の離散構造データを計算機上にコンパクトに表現し, 等価性・正当性の検証,モデルの解析,最適化などの処理を効率よく行う技法は, 計算機科学の様々な応用分野に共通する基盤技術として非常に重要である. 応用分野としては,ハードウェア・ソフトウェアの設計, 大規模システムの故障解析,制約充足問題,データマイニングと知識発見, 機械学習と自動分類,バイオインフォマティクス,ウェブ情報解析等,多種多様であり, 現代社会に対する大きな波及効果を持つ.
離散構造に関する最も基本的なモデルの1つとして論理関数がある. 論理関数を計算機上で処理する工学的技法に関しては, 古くは1938年にShannon がブール代数による論理回路の設計法を示したことに始まり, それ以降現在に至るまで長い歴史がある.論理関数のデータ構造としては, 当初は真理値表表現や積和/和積標準形(DNF/CNF)が用いられてきたが, 1986年に R.E.Bryant が BDD (Binary Decision Diagram; 二分決定グラフ) に関する画期的な論文を発表して以降, BDD を用いた論理関数の処理技術が急速に発展した.
BDD は,VLSI 設計の分野で考案された論理関数データのグラフによる表現である. これは, 論理関数の値を全ての変数について場合分けした結果を以下のように二分木グラフで表し ,これを簡約化することにより得られる.
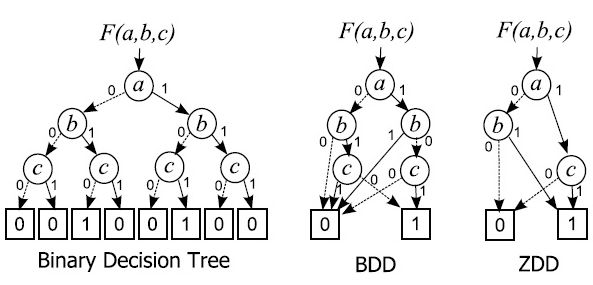
このとき,場合分けする変数の順序を固定し, (1) 冗長な節点を削除する (2) 等価な節点を共有するという処理を可能な限り行うことにより 「既約」な形が得られ, 論理関数をコンパクトかつ一意に表せることが知られている. BDDによるデータ圧縮率は, 論理関数の性質にも依存するが,例題によっては数十倍~数百倍以上もの圧縮 率が得られる場合がある.また,2つのBDDを入力とし, それらの二項論理演算(AND, OR 等)の結果を表す BDD を直接生成するアルゴリズムが知られており, ハッシュテーブルを巧みに用いることで,データが計算機の主記憶に収まる限りは, その記憶量にほぼ比例する時間内で論理演算を効率よく実行できるという特長を持っている. BDD はオンメモリの大規模論理データ処理系であり, メモリにランダムアクセスできる計算機モデルの能力を最大限に引き出す技法とも言える. 近年の PC の主記憶の大規模化により, 従来は記憶容量不足で扱えなかった規模の問題が現実的に扱えるようになったため, 特に2000年以降,BDD の応用範囲が拡大している.
BDD は,元々は論理関数の表現法であるが,n 個の要素からなる集合の各要素を, n 変数の論理関数の入力変数に対応付けることにより, 集合族データを表現することもできる. BDD 表現は, 類似する部分集合が多く含まれるような集合族データを表現する場合に顕著なデータ圧縮効果が得られ, 高速な演算処理が可能となる.このような性質から, BDDは,VLSI 論理設計の分野だけではなく,様々な制約充足問題の解法や, 大規模システムの故障解析など, 0/1 の論理の組合せや集合を扱う多種多様な問題に応用されるようになった.
このような集合族データの処理に特化したBDDとして, 湊研究総括が1993年に考案・命名したものが ZDD(Zero-suppressed BDD; ゼロサプレス型 BDD)である. ZDDは通常のBDDと異なる簡約化規則を持つ. すなわち以下の図に示すように1-枝が 0-終端節点を直接指している場合に, この節点を取り除く.
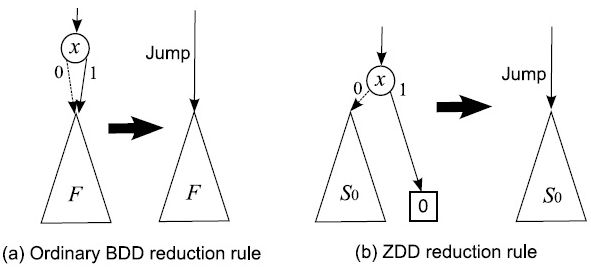
その代わり,通常のBDDで削除されるような節点は削除しない. この簡約化規則は,特に疎な集合の族を表現する際に顕著な効果がある. 例えば,集合要素の平均出現頻度が1%以下であれば, ZDD は BDD より100倍コンパクトになる可能性がある. 世の中で扱われる実問題では,集合要素の平均出現頻度が非常に小さい場合が多い (例えば,店舗での陳列商品の総数に比べて,顧客が1度に購入する商品数は 極めて少ない)ため,ZDD による圧縮効果は極めて大きい. ZDD は,BDD の改良技術として世界的にも広く定着しており, BDD と並んで標準的に使われている. 特に,最近では, データマイニング・知識発見への応用分野で ZDD の有効性が示されている.
以上のように,BDD は当初は LSI 設計自動化の分野で考案・ 発展してきたものであるが,ZDD を始めとする BDD の進化形がいくつか考案され, 広く計算機科学全般に応用範囲が広がっている.
プロジェクトの構想
本プロジェクトでは,前述の BDD/ZDDを基盤とした離散構造処理系の開発ならびにその応用技術の開発を目指している. 本プロジェクトが対象とする技術領域は以下の図で示される「離散構造処理系」 の部分に該当する.
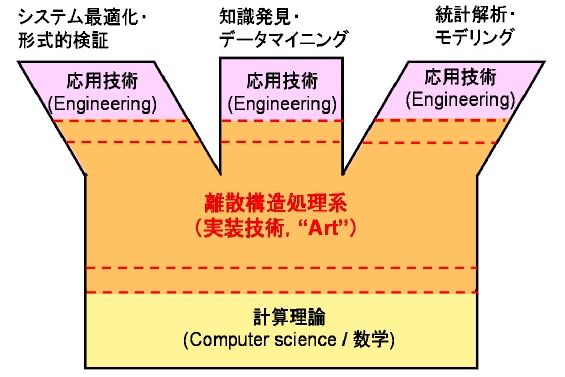
計算機科学の基礎部分には分野横断的な計算理論の領域がある. 一方,実問題を解くために様々な工学的応用に特化した技術領域が多数並列に存在している. その中間層として,本研究が扱う離散構造処理系の技術領域が存在する. この層は,上下の層との境界は明確ではないが,研究の指向性が異なる. 概念的・理論的成果だけではなく, 実用に耐えるアルゴリズムを実装することを重視する. しかし,各応用分野の固有の問題にアドホックに対応するのではなく, 技術基盤としての簡潔さや汎用性を重視する. この指向性こそが Science と Engineering をつなぐ,いわゆる「Art」 であると我々は考えている.
本プロジェクトの技術面のポイントは,BDD風の考え方 (膨大なデータを圧縮したままで効率よく計算する) を発展させた新しいデータ構造を追及するところにある. しかもそのデータ構造は, 処理操作のための体系的な演算を伴っていることが重要である. BDD/ZDD は,論理関数や組合せ集合の表現であるが, 本プロジェクトでは,より高次の離散構造, 例えば,ビット列集合や,文字列(sequence)集合, 順列(permutation)集合,分割(partition),DAG,ネットワーク等, 様々な離散構造の代数系に対する処理系の開発を目指している.